
In the previous article of this series we introduced the problem with queries using literals which are beyond statistics histogram, but exist in the table. We saw that this can be a serious problem in large tables in SQL Server 2012. We saw also that SQL Server 2014 handles it better.
In this article we’ll see how to solve this problem in previous versions of SQL Server.
Whenever performance problems are caused by stale statistics one of the possible solutions is to update statistic. However, this process is resource and IO intensive and as soon as the update is finished new rows come in the table and statistics is again out of date. Of course, the amount of newly added or updated data is significantly reduced with regularly updates.
It is recommended to schedule update statistics on most frequently used key ascending columns in volatile tables to reduce discrepancy between actual data distribution and those in the statistics histogram. Even if you schedule statistics update for a large table the most recent entries are again beyond statistics histogram. With the update statistics we can reduce impact of rows missing in the statistics histogram, but what we can do if update is too expensive? How can we help optimizer when statistics are stale on the key ascending columns? The answer: by using trace flags.
Let’s show again the query and the execution plan from the previous post:
SELECT * FROM dbo.Orders
WHERE custid = 160 AND orderdate >= '20140101' AND orderdate < '20150101';
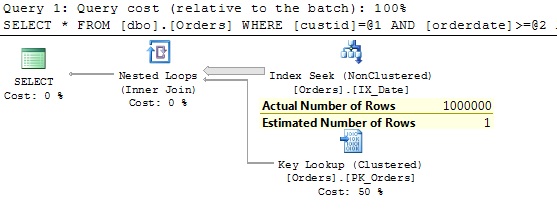
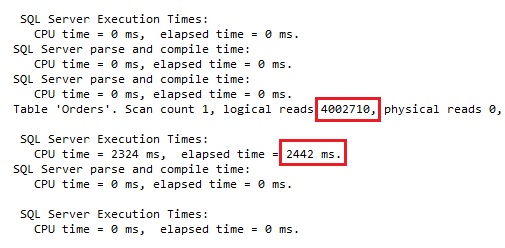
If we would execute the same query with the trace flag 2390 the estimations and execution details looks significantly better:
SELECT * FROM dbo.Orders
WHERE custid = 160 AND orderdate >= '20140101' AND orderdate < '20150101' OPTION(QUERYTRACEON 2390);
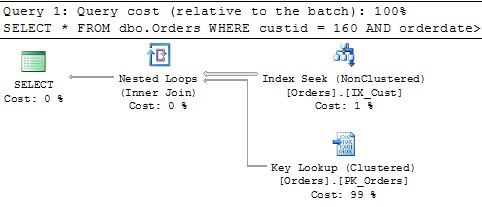
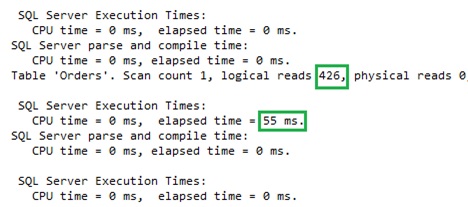
Using TF 2390 helped the optimizer to choose the proper execution plan with an Index Seek on the custid column and execution details looks as we expected.
What is the estimation number of rows for the orderdate predicate only with the TF 2390? Let’s check the estimated execution plan:
SELECT * FROM dbo.Orders WHERE orderdate >= '20140101' AND orderdate < '20150101' OPTION(QUERYTRACEON 2390);
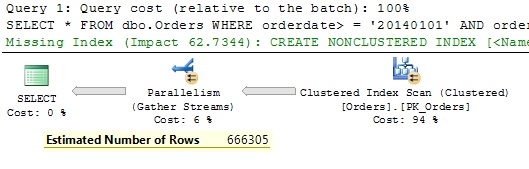
The old CE in SQL Server 2012 with the TF 2390 estimates about 666K rows. Just to remind you that the new CE comes up with 90K. This difference is important and we’ll discuss it in the next post. For this query it’s clear that the other predicate is winner when we use selectivity as criteria and there is no doubt for the Query Optimzer regarding the index usage.
How it gets the devil number of Ks for the Estimated Number of Rows? What’s the magic behind the TF 2390?
To check this we’ll create an Extended Event Session and add the event sp_statement_completed. It is recommended to limit the session to get only events for the specific database. Here is what we collected when we executed the above query:
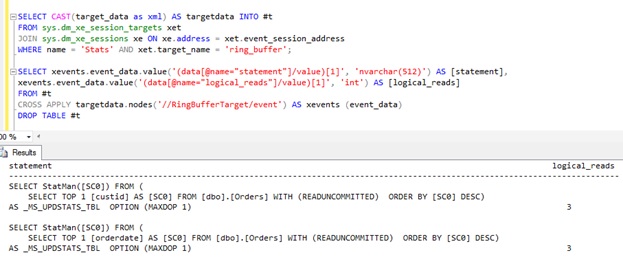
We see two queries doing some statistics calculations by using the max value from the actual table for both columns involved in the query: custid and orderdate. The estimated number of rows of 666K strongly correlates to the expression (last order date from the actual table – max RANGE_HI_KEY from stats histogram) * average number of orders per day. It assumes uniform distribution of data beyond the stats histogram which is in case of the ordering system a reasonable assumption. The estimation of 666K compared to 1M of actual rows is a good estimation. (Especially compared to the default estimation (without TF) of 1 or 90K from SQL Server 2014) Our statistics object has been created automatically when we created the index on the orderdate column (see appropriate code in the previous post). If we wold have only statistics object (auto- or manually created) but without an index, TF 2390 would not improve performance. It requires an index on the column; otherwise it is not able to efficiently find the maximum value. The statistics is created on the fly and does not persist in the system. For more details you can find in the Dmitry Pilugin’s (blog | twitter) excellent article series..
Now we have a good estimation for the orderdate predicate; for the custid we had it anyway. The literal used for the custid (160) isn’t behind the histogram. Why then SQL Server calculated statistics on the fly of it too? TF 2390 instructs SQL Server to perform this calculation against all columns which participate in the filter criteria regardless of used literals. For instance, even if we would look for orders from 2013 which are in the histogram, the stats calculation on the fly would be performed. Actually, not for all columns; it will work for all columns which Leading column Type is Ascending or Unknown. For columns with the leading type Stationary no stats will be calculated on the fly and therefore these columns cannot have benefits from the TF 2390. I will cover all three leading types and how to handle differences in the next post.
How to find out the column leading type? This is detailed described in the excellent article Statistics on Ascending Columns written by Fabiano Amorim (blog | twitter). Again we need a trace flag. This time TF 2388.
DBCC TRACEON(2388);
DBCC SHOW_STATISTICS(Orders, IX_Date);
DBCC TRACEOFF(2388);
When TF 2388 is switched on DBCC SHOW_STATISTICS shows additional info about statistics objects. One of additional attributes is leading column type.

We can see that SQL Server does not know the leading column type for the column orderdate; it is marked as Unknown. Therefore TF 2390 does statistics calculation on the fly when this column participates in filter expressions. Default behaviour of the query optimizer is to use meta data and statistics information during the plan generation, the table or index structure are not touched at all. By using TF 2390 this is not true, SQL Server touches the appropriate index in order to calculate statistics on the fly as a part of good enough plan finding.
Conclusion
The problem with queries using literals which are beyond statistics histogram can be solved in SQL Server 2012 by using TF 2390. Instead of estimation of 1 row the QO estimates by non-persistent statistics calculation on the fly. This brings a small overhead since the calculation on the fly will be performed against all columns participating in filter expressions (not only on those where it is required), but it is anyway better as default CE behavior prior to SQL Server 2014. The solutions done by TF 2390 and old CE and new CE in SQL Server 2014 for this query pattern looks similar, but some companies don’t allow usage of trace flags in th eproduction system. Therefore for them the recommended solution is to use SQL Server 2014 CE. But again, for this query pattern, not for all of them!
Thanks for reading.
