
In the previous articles we’ve covered differences in estimations between the old and new CE related to queries that use predicates with literals which values are beyond the statistics histogram. We saw some issues with key ascending columns in SQL Server 2012 which can be solved with the trace flags 2389, 2390 and 4139. And we saw that the same queries perform well in SQL Server 2014 without flags. It seems that this is a reason why these flags are not supported in the newest SQL Server version.
You can find some articles about new CE and all of them wrote about improved estimations for key ascending column queries in SQL Server 2014. You can think that there is no problem with key ascending columns anymore. This is only particularly true. In this article I will show you another query pattern with significant performance regression in SQL Server 2014.
Key Ascending Problem Solved?
In one of my previous articles Beyond Statistics Histogram – Part 1 we saw that the same query performs significantly better in SQL Server 2014 (from more than 4M to 455 logical reads) and that the new CE, opposite to the old CE, does not estimate 1 row whenever a value beyond stats histogram is used in a predicate. It estimates significantly more. More enough to govern the Query Optimizer to use a correct index. The problem described in the mentioned article (a most common ascending key problem) is caused by the estimation of 1 for the orderdate predicate. In this concrete case it would be enough to estimate more than 110 rows (which is the estimate for the custid predicate) and the Query Optimizer would use the index on custid, as we initially expected. So, the new CE did it – it estimated 90.000, significantly more than needed, and the plan was OK – the problem solved.
But where did this estimation come from? That’s an interesting question, maybe irrelevant in this particular example, but it definitely deserves an answer.
Let’s create a new sample table and populate it initially with 1M rows and add then additional 100K rows by using this code. As we saw in previous posts this is not enough to trigger statistics update and the statistics object still see only orders until 31.12.2013. Now when we have a sample table and sample data let’s implement our very simple requirement: to return all orders from yesterday and today, sorted by amount descending. Here is the solution::
SELECT * FROM dbo.Orders WHERE orderdate >= DATEADD(DAY,-1,GETDATE()) ORDER BY amount DESC;
A very basic query with expected Index Seek on the orderdate index followed by Key Lookup, since we don’t expect more than 500-600 rows. And this is exactly what we get. In SQL Server 2012.
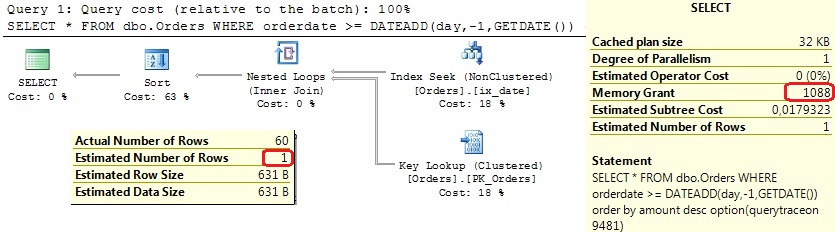
What about SQL Server 2014? Well, “a little bit different”…
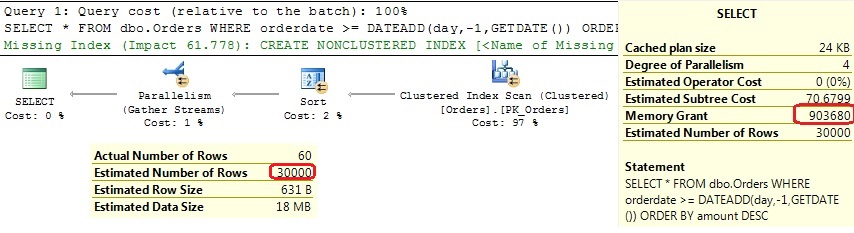
A clustered index scan and memory grant of 900 MB to return and sort 60 rows only! And yes, this is again a “key ascending problem”. And it is not solved. It is actually introduced with the new CE! There is no such problem under the old CE! OK, the old estimation of 1 was not correct, but it’s definitely better than 30.000 given by the new CE. You can even fix the estimation of 1 under the old CE by using TF 2390, which was the solution for the key ascending problem before SQL Server 2014. Let’s execute the same query with TF 2390:
SELECT * FROM dbo.Orders WHERE orderdate >= DATEADD(DAY,-1,GETDATE()) ORDER BY amount DESC OPTION (QUERYTRACEON 9481, QUERYTRACEON 2390);
And now observe the execution plan:
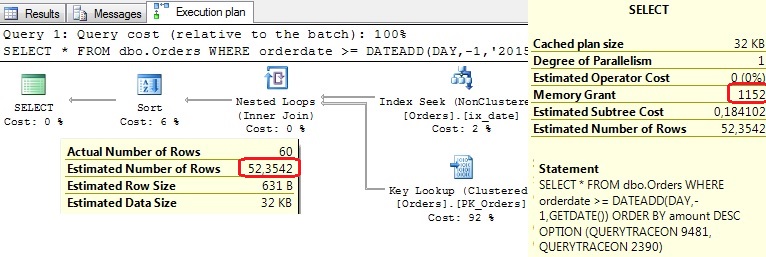
You can see an excellent estimation and expected execution plan with appropriate memory grant. So, with the old CE we have one acceptable and one excellent execution plan. With the new CE a suboptimal one with significantly overestimated memory grant.
New CE simply ignores literals if they are beyond the statistics histogram. It simply estimates 30% of the total number of modifications for the leading statistics column since the last time statistics were updated. In our case this number is 100.000 and the estimation is then 30.000. And the new CE has the same estimation (30.000) for the following two queries:
SELECT * FROM dbo.Orders WHERE orderdate >= '20150314' OPTION (RECOMPILE);
SELECT * FROM dbo.Orders WHERE orderdate >= '34450101' OPTION (RECOMPILE);
In case of BETWEEN operator the estimation is 9% of the modification_counter value, but again the literals are completely ignored. I am not happy with this fact at all. The estimation done by the old CE was hardcoded to 1, but the new CE has hardcoded it too, not to the constant, but to the expression (i.e. modification_counter * 0.3 for > or <, modification_counter *0.09 for BETWEEN etc.). To make the problem even worse, the trace flags 2389, 2390 and 4139 are not supported in SQL Server 2014 and you cannot force the optimizer to re-calculate statistics object on the fly. This functionality would help here, but it is removed. I created the following Connect Item for this issue. If you think that this could be useful please vote for it.
Conclusion
The key ascending problem caused by constant underestimation in SQL Server 2012 can lead to significant performance problems with the default QO behavior. However, with TF 2389, 2390 and 4139 the problem can be solved with acceptable costs. With the new Cardinality Estimator in SQL Server 2014 the problem disappear for common query patterns, but the execution of some other queries, which perform well in old SQL Server versions, shows significant performance regressions. New CE significantly overestimates number of rows for predicates using literals beyond the statistics histogram which usually induces an execution plan with the scan of large tables. Unfortunately all trace flags which are helpful in previous versions are not supported anymore. We hope, however, that this functionality still can be back, at least until the status of the corresponding connect item is active.
Thanks for reading.