
In this article I will explore changes in new CE related to column correlation. As mentioned in my first article about new CE, this change is announced in the paper Testing Cardinality...
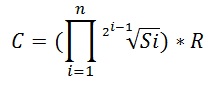
SQL Server Performance
In this article I will explore changes in new CE related to column correlation. As mentioned in my first article about new CE, this change is announced in the paper Testing Cardinality...