
In this article, I will demonstrate a small change in the Cardinality Estimator component under the latest compatibility level – 150 (SQL Server 2019). Let’s first create and...
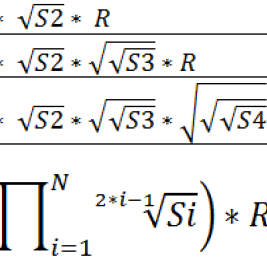
In this article, I will demonstrate a small change in the Cardinality Estimator component under the latest compatibility level – 150 (SQL Server 2019). Let’s first create and...