
In this article, I will demonstrate a small change in the Cardinality Estimator component under the latest compatibility level – 150 (SQL Server 2019).
Let’s first create and populate a sample table:
DROP TABLE IF EXISTS dbo.T;
CREATE TABLE dbo.T(
id INT IDENTITY(1,1) NOT NULL,
c1 INT NOT NULL,
c2 INT NULL,
c3 CHAR(5) DEFAULT 'test',
CONSTRAINT PK_T PRIMARY KEY CLUSTERED (id)
);
GO
CREATE INDEX ix1 ON dbo.T(c1);
GO
CREATE INDEX ix2 ON dbo.T(c2);
GO
INSERT INTO dbo.T(c1)
SELECT 1 + ABS(CHECKSUM(NEWID())) % 10000
FROM dbo.GetNums(1000000);
GO
--update the c2 column to not null for about 5% rows
UPDATE dbo.T SET c2 = c1 WHERE c1 >= 9500;
GO
Ensure that the database runs under the compatibility level 140 and consider the following simple query with a local variable:
ALTER DATABASE New SET COMPATIBILITY_LEVEL = 140;
GO
DECLARE @v INT = 600000;
SELECT * FROM dbo.T WHERE c1 = @v;
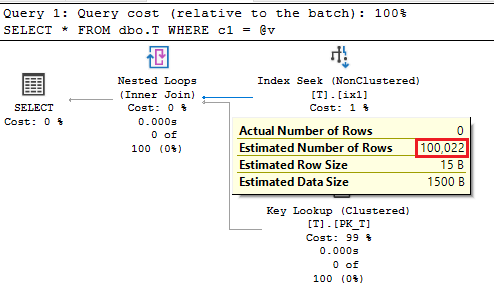 This is a very known situation – an estimation for an equality predicate with local variable. The estimated number of rows is calculated as the All density attribute from the stats density vector multiplied by the Rows from the stats header.
This is a very known situation – an estimation for an equality predicate with local variable. The estimated number of rows is calculated as the All density attribute from the stats density vector multiplied by the Rows from the stats header.
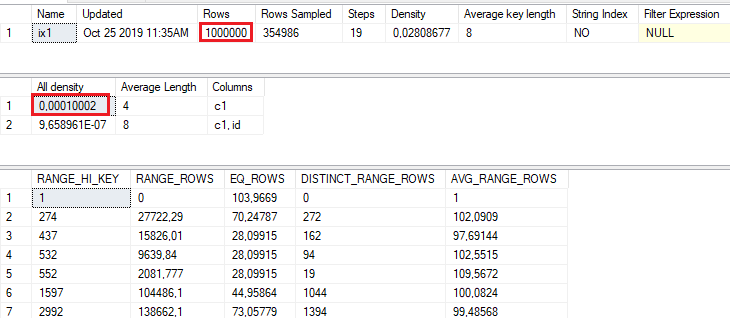
SELECT 0.00010002*1000000;
--100.02000000
The c1 column does not allow NULLs. What would be the estimation for a nullable column? The c2 column in our table is nullable. Let’s have a check:
DECLARE @v INT = 600000;
SELECT * FROM dbo.T WHERE c2 = @v;
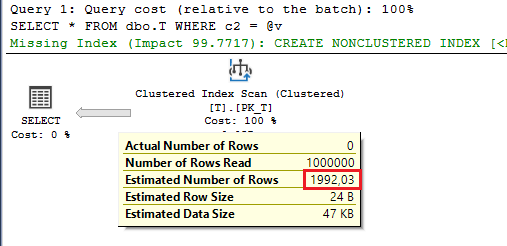
The estimation is significantly higher and even lead to a plan with Clustered Index Scan! However, it follows the same formula for the estimation. Let’s have a look at the statistics object:
By using the same formula, the estimated number of rows is:
SELECT 0.001992032*1000000
--1992.032000000
This is exactly what we see in the execution plan. OK, that was CL 140, let’s see how SQL Server 2019 handles this simple case.
When we switch to CL 150, the plan and estimations for the c1 column (non-nullable) are the same. However, the estimation for the nullable column is changed!
ALTER DATABASE New SET COMPATIBILITY_LEVEL = 150;
GO
DECLARE @v INT = 600000;
SELECT * FROM dbo.T WHERE c2 = @v;
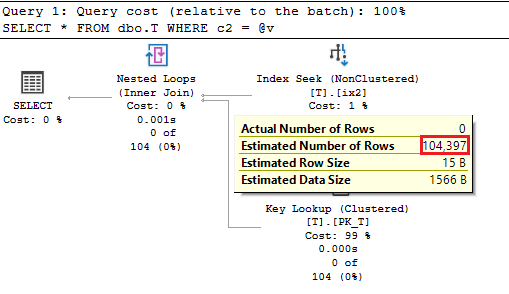
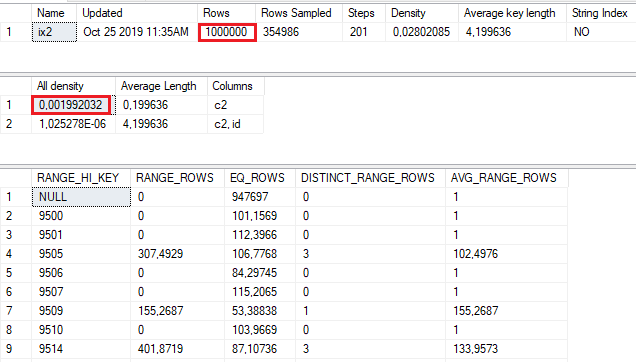
This time, the estimation is not so high, and we are getting more appropriated plan, based on the Nested Loop join operator. But, where is 104.397 coming from? Let’s look at the statistics again:
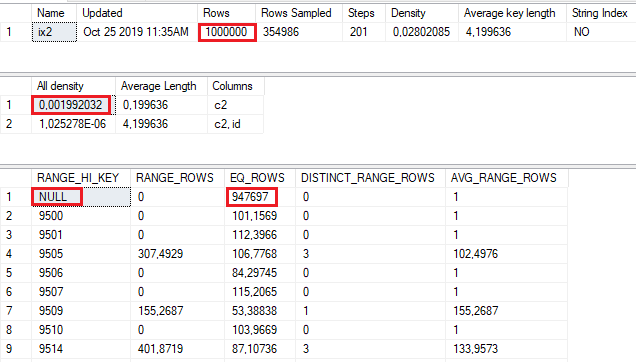
Since the column is nullable, CE apply the All density against non-nullable rows only. Thus, the formula seems to be All density x (Rows – EQ_ROWS for RANGE_HI_KEY = NULL).
SELECT 0.001992032*(1000000-947697);
--104.189249696
Well, it is not exactly 104.397, but very, very close to it. I did not find official documentation for this, therefore cannot confirm that the mentioned calculation is always correct. However, this new behavior makes more sense: the average value from the stats density vector refers to non-nullable set of values, and it’s wrong to multiply it with all rows.
Funfact – the behavior is actually not new at all – that’s exactly how the old CE (under the compatibility levels <=110) handles this case.
I would like to thank my colleague Vladimir Đorđević for making me aware of this behavior.
Thanks for reading.
