
As mentioned in the previous article, SQL Server 2019 cardinality estimations for a table variable are based on actual table variable row counts. Therefore, in SQL Server 2019, we should expect better estimations and better plans for queries that use table variables.
Which queries will benefit from this improvement? Generally, queries that use table variables with a lot of rows in them, which are not tuned yet. For table variables with a few rows, there will not be significant changes and you should expect the same execution plan and almost same execution parameters.
Queries whose execution was slow due to underestimation in table variables usually implement logical joins by using Nested Loop Join physical operator where a Hash or Merge Join operators would be more appropriate. In addition to this, underestimation of table variables participating in multiple joins could lead to issues with insufficient memory grants, and thus data spilling to tempdb .
For instance, the following query stores ProductIds in a table variable, and in the next statement returns all order details related to them. We’ll execute it under compatibility levels 140 and 150, to see the difference in the executions between usual and deferred table variable compilation. Let’s execute first the query under CL 140:
ALTER DATABASE AdventureWorks2019 SET COMPATIBILITY_LEVEL = 140;
GO
DECLARE @T AS TABLE (ProductID INT);
INSERT INTO @T SELECT ProductID FROM Production.Product WHERE ProductLine IS NOT NULL;
SELECT * FROM @T t
INNER JOIN Sales.SalesOrderDetail od on t.ProductID = od.ProductID
INNER JOIN Sales.SalesOrderHeader h on h.SalesOrderID = od.SalesOrderID
ORDER BY od.UnitPrice DESC;
As expected, the execution plan for the second query uses Nested Loop Join operator for all logical Joins, since the cardinality of the table variable is 1, which makes Nested Loop as appropriate choice for join operations.
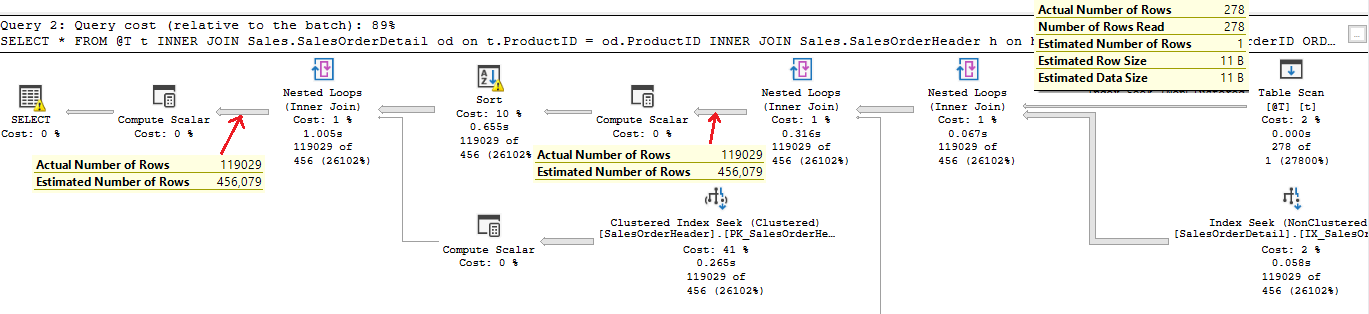
By observing execution plan, you can also see, that the number of rows is highly underestimated. That does not only lead to Nested Loop operators, but also the Sort operator in the plan got a memory grant that is enough for data sorting. The amount of memory would be enough for estimated and not for actual data volume.

This lead to tempdb spilling, since 1MB is not enough for sorting 120K rows. You can see spills in a SQL Server Profiler or Extended Events tracing session (yes, you can still use both of them, Extended Events on production servers and Profiler for demo and testing purposes), as I did during execution of the previous query:

OK, that was CL 140, let’s switch to 150, to see performance improvements:
ALTER DATABASE AdventureWorks2019 SET COMPATIBILITY_LEVEL = 150;
GO
DECLARE @T AS TABLE (ProductID INT);
INSERT INTO @T SELECT ProductID FROM Production.Product WHERE ProductLine IS NOT NULL;
SELECT * FROM @T t
INNER JOIN Sales.SalesOrderDetail od on t.ProductID = od.ProductID
INNER JOIN Sales.SalesOrderHeader h on h.SalesOrderID = od.SalesOrderID
ORDER BY od.UnitPrice DESC;
The plan has been changed; instead of Nested Loop Join operators, you can see Hash Match operators, estimations are significantly better 126K vs.119K, and memory grant is appropriate (140 MB).
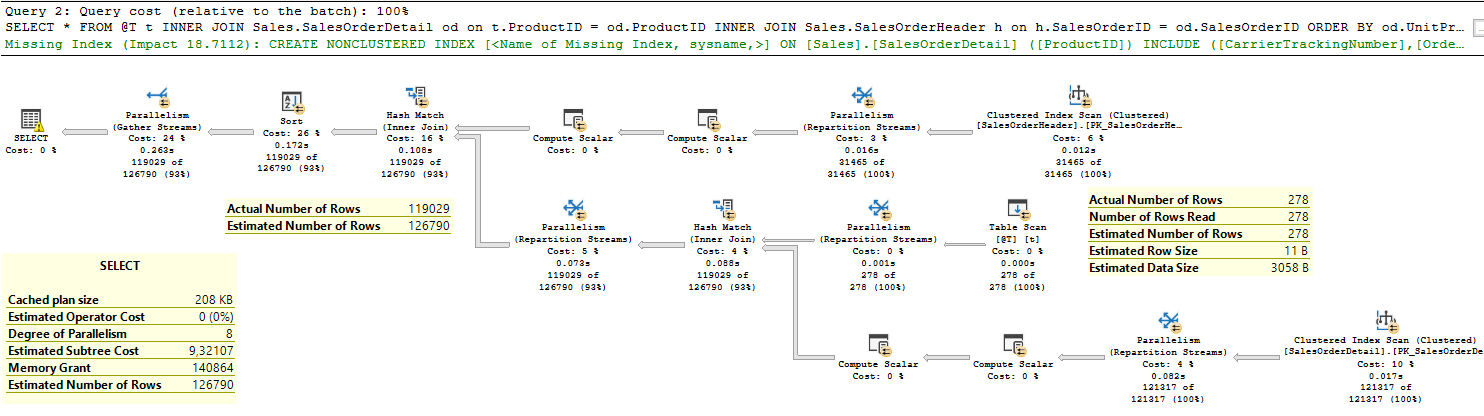
Since memory grant is sufficient, there are no Sort Warnings detected, thus the overall execution looks significantly better under CL 150.
What with the execution time? To compare the execution time, we will use Adam Machanic’s SQLQueryStress tool. It will allow us to run queries multiple time without panting results, so that we can compare the time needed for query execution only. And here are the results:
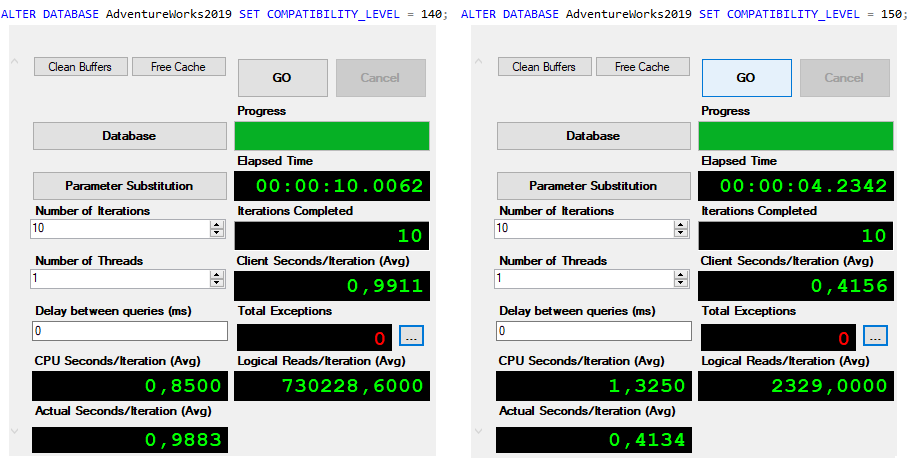
The execution parameters for CL 150 look definitely better, the execution is more than 50% faster, no tempdb spilling and we can conclude that this query is happy with new behavior of table variables in SQL Server 2019.
Which queries are not so happy, you’ll see in the second part of this article.
Thanks for reading.

[…] Milos Radivojevic gives us a good example of when table variable deferred compilation is a good thin…: […]