
In this article I will describe a case which is not properly handled by the new cardinality estimator, introduced in SQL Server 2014 CTP2. The discrepancy between estimated and actual values is significant, generated execution plans are sub-optimal and execution details are 5 – 50x worst compared to the old CE plans,. Since performance regression is significant I would interpret the behavior of new cardinality estimator in this case as a bug.
First we would need a sample table. Let’s create it and populate it with 1M rows. Use the following code to create and populate the test table (the help function dbo.GetNums is developed by Itzik Ban-Gan and you can download it here).
IF OBJECT_ID('dbo.Orders', 'U') IS NOT NULL DROP TABLE dbo.Orders;
CREATE TABLE dbo.Orders(
id INT IDENTITY(1,1) NOT NULL,
custid INT NOT NULL,
orderdate DATETIME NOT NULL,
amount MONEY NOT NULL,
note CHAR(100) NULL,
duedate DATETIME NULL,
CONSTRAINT PK_Orders PRIMARY KEY CLUSTERED (id ASC)
)
GO
-- Fill the table with 1M rows
DECLARE @date_from DATETIME = '19980101';
DECLARE @date_to DATETIME = '20130630';
DECLARE @number_of_rows INT = 1000000;
INSERT INTO dbo.Orders(custid,orderdate,amount, note)
SELECT 1 + ABS(CHECKSUM(NEWID())) % 10000 AS custid,
(SELECT(@date_from +(ABS(CAST(CAST( NEWID() AS BINARY(8) )AS INT))%CAST((@date_to - @date_from)AS INT)))) orderdate,
50 + ABS(CHECKSUM(NEWID())) % 1000 AS amount,
'note' AS note
FROM dbo.GetNums(1,@number_of_rows)
ORDER BY 1
GO
UPDATE dbo.Orders SET duedate = DATEADD(DAY, 14, orderdate)
GO
CREATE INDEX IXo1 ON dbo.Orders(custid)
GO
Prior to SQL Server 2008 we could find a lot of stored procedures with a comma separated list of Ids packed in a VARCHAR(4000) or an XML or with more than 20 parameters. SQL Server 2008 introduced table valued parameters which allow us to pack all input parameters in a table structure and use this structure as stored procedure parameter. Within the stored procedure the table valued parameter behaves as a table variable and can participate in set-based operations. Therefore sometimes filtering of a large table is not implemented with predicates in the WHERE clause but by joining the table to a table variable. For the purpose of this article we would need a query filtering a large persistent table by joining it to a table variable. Let’s define a table variable with two attributes: an integer and a datetime and populate it with only one row:
DECLARE @T AS TABLE(
custid INT NOT NULL,
ord_date DATETIME NOT NULL
);
INSERT INTO @T(custid,ord_date) VALUES(1, '20070806');
Now we want to extract order details for customers whose ID is in the table variable but only with order dates specified in the same variable. i.e.
SELECT o.*
FROM @T t
INNER JOIN dbo.Orders o
ON o.custid = t.custid AND o.orderdate = t.ord_date;
The execution plan and estimation details are shown in the following Figure:
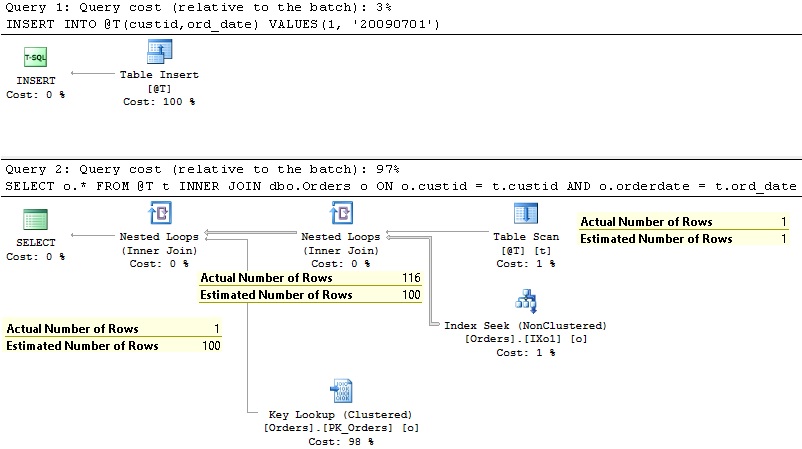
The plan and estimations are identical for both cardinality estimators. Estimated Number of Rows outputted from a table variable did not change in new CE. It is still assumed 1 row. The execution plan shows us that SQL Server scans the table variable and for each entry in it performs an Index Seek to find out if orders exist for this customer ID and then for each so identified customer ID it performs Key Lookup operation which is used for additional filtering – to extract only orders with order date from the table variable and to get additional columns. This is an expected execution plan – we are OK with it, both CEs come up with it – La Vita è Bella…
Let’s slightly change our requirements. Instead of using the orderdate column we will use the duedate column. The difference between these two columns is that values in duedate column are shifted for 2 weeks. An additional difference is that the duedate column is null-able. That requires that we have to clarify our requirements for cases where duedate is not available for some orders. So, we want to return order details for customers which Ids are in the table variable but only for orders with the duedate which matches the value from the table variable. If the value for duedate is not available for an order but customer ID matches the value from the table variable, the order should be returned, too. (I hope it’s clear to me what I wanted to tell here). Let’s make it clear and write the query:
DECLARE @T AS TABLE(
custid INT NOT NULL,
ord_date DATETIME NULL
);
INSERT INTO @T(custid,ord_date) VALUES(1, '20090701');
SELECT o.*
FROM @T t
INNER JOIN dbo.Orders o
ON o.custid = t.custid AND (o.duedate= t.ord_date OR o.duedate IS NULL)
OPTION(QUERYTRACEON 9481); --old CE
GO
DECLARE @T AS TABLE(
custid INT NOT NULL,
ord_date DATETIME NULL
);
INSERT INTO @T(custid,ord_date) VALUES(1, '20090701');
SELECT o.*
FROM @T t
INNER JOIN dbo.Orders o
ON o.custid = t.custid AND (o.duedate= t.ord_date OR o.duedate IS NULL); --new CE
Let’s observe the execution plans and the most important execution details. First with old CE:

And now the plan and execution details under new CE:
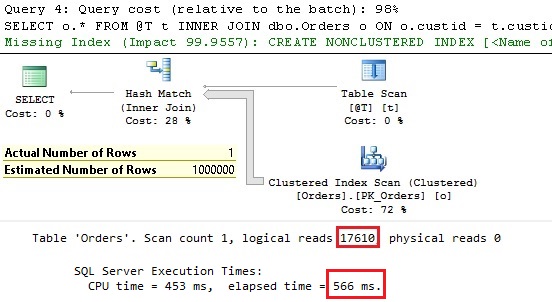
The execution details with new CE definitive don’t look good. Instead of expected Nested Loop Join operator (expected because we have only one customer id and additional filter on the duedate) we see Hash Match Join operator handling a join between table variable with one row and the Orders table. We can see that the Orders table is fully scanned and that the index on the custid is completely ignored. As result we see significant estimation discrepancy with the order of magnitude 6! Of course the missing estimation resulted with 50 times more logical reads and 5 times longer response time with significant CPU activity. At the same time the old CE handles this situation correct and according to expectations. The same problem occurs if a temp table is used instead of table variable. It will also not help to replace the OR statement by the functions ISNULL or COALESCE. The same issue.
Workaround
Is there any workaround? Yes, we could use the query hint LOOP JOIN and force the optimizer to use Nested Loop Join operator instead of Hash Match Join. Let’s see if it works:
DECLARE @T AS TABLE(
custid INT NOT NULL,
ord_date DATETIME NULL
);
INSERT INTO @T(custid,ord_date) VALUES(1, '20090701');
SELECT o.*
FROM @T t
INNER LOOP JOIN dbo.Orders o
ON o.custid = t.custid AND (o.duedate= t.ord_date OR o.duedate IS NULL); --new CE
Let’s observe the execution plan:
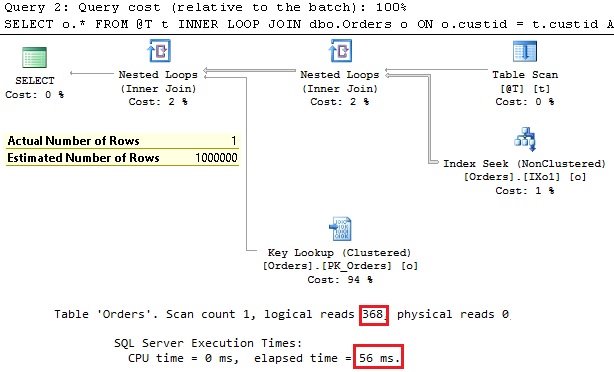
So, the execution plan is identical to the plan generated by the old CE, logical reads and execution times are also OK. It seems that we found a workaround. The only remaining problem is this bad estimation. Our query hint affects the choice about physical join operator but all estimations remain untouchable. However, in this case it does not matter, according to execution parameters. We got the same performance as with the old CE. Intuitively, we suspect that something could be wrong – we don’t want to see such estimation discrepancy, even if the plan and execution look OK. Or estimations are irrelevant when we use query hints? No, they are still relevant and still could affect performance. Soon we’ll see how.
Let’s slightly change our query (in the last version with the LOOP JOIN hint) and put the ORDER BY o.amount at the end of the query. Now let’s execute so modified query and look at the execution plan:
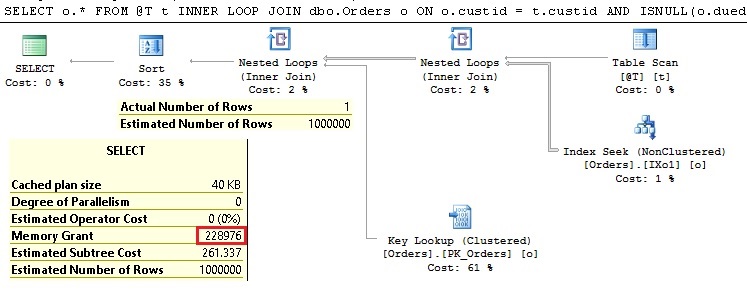
Adding the ORDER BY in the query affected the execution plan and now we can see a Sort operator. Sort operator requires memory and we can see that for this purpose the query requested 228 MB of memory. Just to remind at this point that our query returns only one row and since the Sort operator is at the end of the data flow (after all unnecessary rows are discarded) we would expect a minimal memory grant (1MB). However, memory is not granted according to our expectations, but according to cardinality estimations and SQL Server expects 1M rows to be sorted – therefore 228 MB is requested (and granted) for sorting purposes. Actually it would request memory grant which is enough to sort the whole Orders table. This wasting of memory can be important and can significantly degrade overall performance! So, be careful whenever you see significant discrepancy between Estimated and Actual Number of Rows. It could be that you still don’t have problem with it, but the potential for it is great.
Conclusion
It seems that new optimizer does not handle well joins between table variables (or temp tables) and regular tables when null-able columns are involved in join conditions. Regardless of number of predicates in the ON clause if a null-able column is included and its predicate has to return true if the value is missing (NULL) the new CE ignores all the other predicates and selectivities and perform the full table scan. As a result the execution plan uses a Hash Match Join operator even if only few rows are returned. As opposed to the new CE the old CE estimates well and the execution plans are good. A workaround for this problem could be a query hint LOOP JOIN if there is no operator which require memory, or to use OPTION(QUERYTRACEON 9481) to instruct the optimizer to use the old cardinality estimator. Or to wait for a fix in the RTM Version or a cumulative update.

We are also hit by this bug in the new CE. We are heavily using table variables joined to a main disk table. The new CE is terrible at estimating the row count out of a table variable.
If you can reliably reproduce the problem – make a connect entry, so that we can all vote and hope its fixed soon. 5 years ago I have battled MS (successfully at the end :)) over another bug, which then was in the query executor engine but I’m too tired to do it again 🙂
Ivan, thanks for the comment. I already created one connect item regarding new CE behaviour for out-of-histogram estimations (http://bit.ly/1zoPbuD), let’s how it will ends up 🙂
Regarding this issue here, new CE does not have a different estimation for table variables, it’s still 1, so equaly good or wrong as we had it with the old CE. Here is simple a bug in the handling an expression with the OR operator. If we would rewrite the query to avoid OR, for instance:
SELECT o.*
FROM @T t
INNER JOIN dbo.Orders o
ON o.custid = t.custid AND o.duedate= t.ord_date
UNION
SELECT o.*
FROM @T t
INNER JOIN dbo.Orders o
ON o.custid = t.custid AND o.duedate IS NULL;
the plan looks OK, without table scan and Hash Join. So, the same table variable joined with the same table and a logical equivalent expressions but different and correct execution plan. So, the problematic part is handling the OR operator in the predicate.
You are right, it deserves a connect item.
Thanks!
Rgds,
Milos
[…] pattern where new CE in SQL Server 2014 brings significant regression. And, similar to the case in this post I would interpret the behavior of new cardinality estimator in this case as a bug, […]